2023. 1. 9. 12:52ㆍML
저번 글에서는 Boosting에 대해서 알아봤는데요.
이번 시간에는 머신러닝에서 많이 사용되고 있는 알고리즘인
MLP와 RNN에 대해서 알아보도록 하겠습니다.
1.MLP(Multi Layer Perceptron)
MLP에 대해 먼저 알아보기 앞서 Perceptron에 대해서 알아볼 필요성이 있습니다.
Perceptron의 개념은 사실 매우 간단합니다.
각각의 변수마다 각각의 가중치를 곱해서 모두 더한후 함수를 이용해 나타내는 방식인데요

위 그림을 보면 쉽게 이해가 가실 겁니다.
편향을 표현하기 위한 1을 제외 하고 각각의 변수마다 가중치를 이용해서 y값을 1 또는 -1로 구분할 수 있게 하는 것이 바로 perceptron입니다.
또한 이렇게 계산을 하면서 가중치를 정답에 맞게 업데이트하고 출력이 정답과 같게 되면 이제 멈추게 되고 이진 분류를 할 경우에 많이 사용합니다.
그렇다면 MLP는 왜 개발되었을까요?
기존의 Perceptron은 이진 분류에 매우 유리했지만 이제 정확히 이진 분류에 불가능한 현실 문제들을 해결하기 위한 방법으로 개발된 것이 바로 MLP입니다.
기존의 Perceptron은 변수마다 하나의 가중치를 이용하여 계산을 했다면
MLP에서는 하나의 변수에 여러가지 가중치를 모두 이용하는 방법을 사용합니다.

위 그림에서 볼 수 있듯이 Perceptron과는 다르게 layer라고 부르는 줄들이 이제 한 줄이 아니고
Hidden Layer라고 불리는 노드를 보면 한 개의 변수가 아닌 여러 개의 변수를 여러 개의 가중치를 이용한 값들을 합쳐서 계산하는 것을 볼 수 있습니다.
그리고 각각의 노드들을 이용해서 출력값을 나타내게 됩니다.
물론 Perceptron처럼 이제 출력값을 정답과 맞추어야 하기 때문에 가중치를 업데이트하는 과정이 필요합니다.
이 과정에서 Backpropagation(역전파)라고 불리는 알고리즘이 사용되는데요.
말 그대로 진행 방향의 뒤로 다시 정보를 전달하는 방법을 사용하는 것입니다.
처음 구했던 출력값과 정답의 차이를 가중치에 대하여 미분한 후에 그 차이값이 최소가 될 수 있도록 가중치를 업데이트 하는 방법을 Backpropagation이라고 정의합니다.
이 역전파 방법을 통해서 MLP는 정답과 동일한 출력값을 만들게 되는 것입니다.
코드로 한 번 살펴보겠습니다.
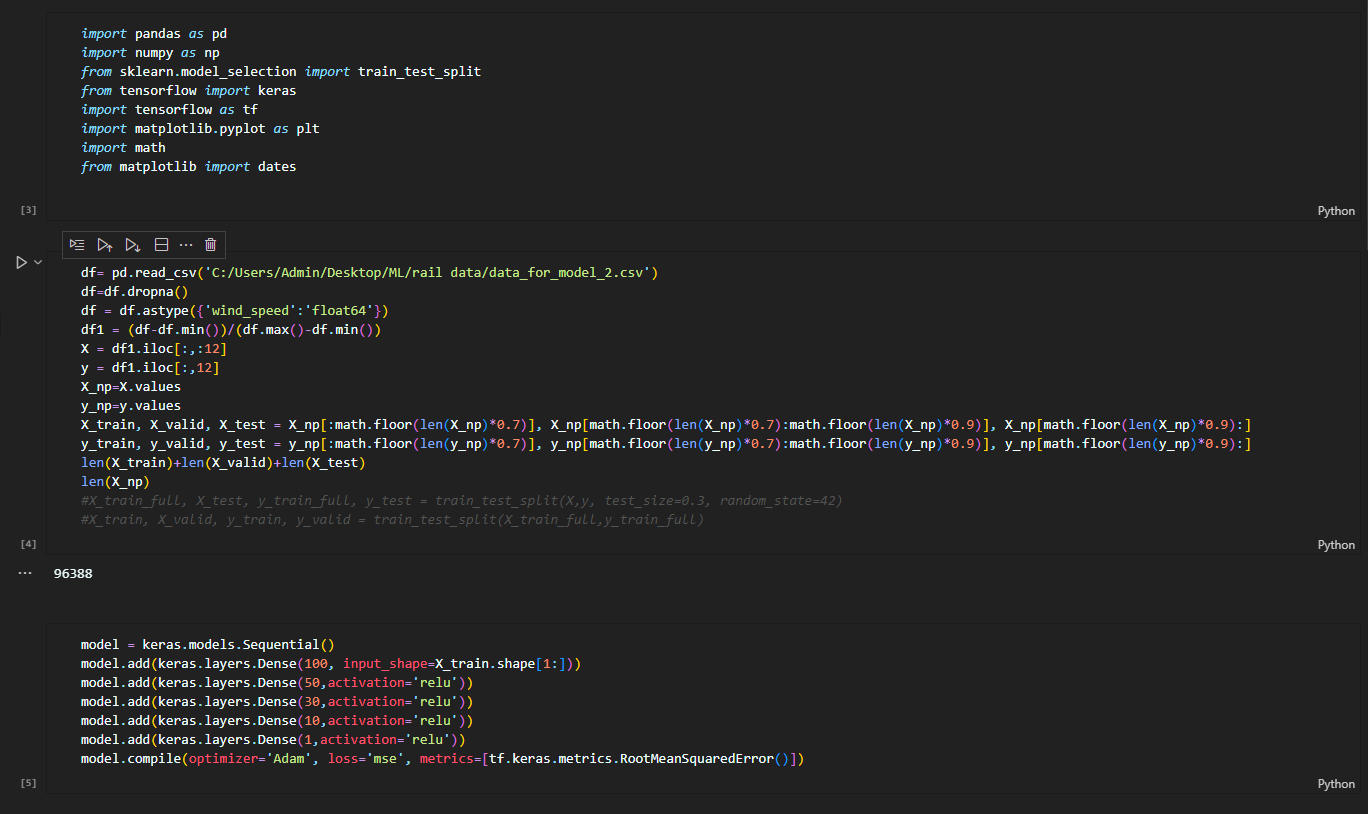
batch_size=100, epochs=100으로 훈련시킨 결과 아래 그림들처럼 나쁘지 않은 정확도로 예측을 잘하는 것을 볼 수 있습니다.


2.RNN(Recurrent Neural Network)
이번에는 RNN에 대하여 알아보도록 하죠
RNN은 순환신경망이라고 불리는데 배열의 형태를 갖는 데이터(글, 유전자, 손글씨, 센서데이터, 주가 등)의 패턴을 인식하여 학습하기 위한 신경망입니다.
특이하게도 등장했던 패턴을 기억하는 특성을 가지고 있어서 시간에 따른 data를 판단하는데 아주 유용하게 사용되고 있습니다.

위 그림으로 보면 어떤 느낌인지 이해가 쉽게 가실 겁니다.
기존의 알고리즘들과는 조금 다르게 HIdden Layer에서 다시 돌아오는 무언가를 찾으실 수 있을 겁니다.
t-1에서의 hidden layer을 이용해서 t에서의 hidden layer 계산에 사용하고
t에서의 hidden layer을 이용해서 t+1에서의 hidden layer 계산에 이용한다는 것을 알아채셨을 겁니다.
이처럼 이전에 사용했던 정보들을 유용하게 사용함으로써 반복적이고 순차적인 데이터 학습을 매우 빠르게 처리해낼 수 있다는 장점을 가지고 있습니다.
RNN 같은 경우에는 코드가 상당히 복잡하므로 중요한 코드만 집고 넘어가보겠습니다.

epochs=10으로 훈련시킨 결과 나름 정확하게 예측된 것을 확인할 수 있습니다.


위에서 설명 한 장점도 존재하지만 먼 과거 상태를 사용하는 경우에는 학습 능력이 현저하게 떨어진다는 단점 또한 가지고 있습니다.
이를 보완하기 위해 요즘은 LSTM(Long Short-Term Memory)이라는 알고리즘을 사용하기 있는데 이 알고리즘은 다음에 따로 알아보도록 하겠습니다.
'ML' 카테고리의 다른 글
| XGBOOST Algorithm (0) | 2023.01.09 |
|---|---|
| RandomForest Algorithm (0) | 2022.12.21 |
| 머신러닝 공부를 위한 두 번째 정리 (0) | 2022.12.11 |
| 머신러닝 공부를 위한 첫 번째 정리 (1) | 2022.12.11 |